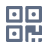-
Products
-
Solutions
-
Trial

-
Docs
-
About Us


 Metaverse
Metaverse 游戏中的社交模块不仅能够增加游戏的玩法,还能提高玩家的粘性,已经成为仅次于玩法设计的第二核心功能。但是几乎每一款带有公共聊天频道的游戏,都会遭遇“虚假礼包”、“工作室刷屏”、“涉政”等之类的问题(如下图所示),这些信息严重影响了用户的游戏体验,甚至会导致用户流失,活跃度下降,此外一些情节严重的违法违规内容会给游戏厂商带来运营风险和负面的社会影响。
针对上述问题,云上曲率推出了文本检测服务,该服务在千亿级游戏语料的支撑下,以深度学习和NLP技术为核心,能够准确识别游戏中出现的文本垃圾信息,主要可分为敏感文本(如涉政、暴恐、种族歧视等)和广告信息。
问题分析
本文主要以文本广告为对象,简要的介绍云上曲率在广告识别方面所采用的技术,目前对接的游戏客户的广告信息基本上可以分为以下几个类别:
1.资源商/工作室广告
如:粮,木,,wοοd,fοōd, 微:二凌贰七七零叁 vvww.ⅯÂⅬⅬⅯⅯО.c0m
2.竞对拉人广告
如:联盟里有想换游戏玩的兄弟吗?可以加我微信一起换游戏玩2076934851
3.其他违规信息
如:晴空61推广61返利端,首日返利百分之70 后续永久返利百分之50 认准晴空V:85659762
大部分的游戏厂商都是通过设置规则进行关键词过滤和屏蔽,但是发布者为了逃避拦截,通常都会对垃圾信息进行伪装,比如拼音替换,同义词替换,象形字替换,嵌入表情字符,甚至将文字顺序打乱。对于复杂的信息,其表达形式广泛,没有规律,仅仅通过规则过滤达不到效果。除变体伪装外,正常玩家在游戏聊天中也会提到买卖资源以及其他游戏相关的内容,这加大了广告识别的难度。针对上述情况,可借助精确的算法模型进行检测。
基于预训练的解决方案
1. 痛点分析
1)数据多, 但是标注数据少, 标注成本高
在工业界做算法应用最令人头疼的问题便是数据了。虽然我们每天可以拿到百万甚至千万级的游戏聊天数据,,但是缺乏标注的数据.。算法模型应用在文本反垃圾上是在做有监督的分类, 如果标注数据太少会使得分类模型很容易过拟合。
最直接的解决方法是增加标注数据,然而我们很难在海量的聊天文本中筛选出足够量的垃圾文本。一方面,整体上垃圾文本占比很低,通过抽样标注的方式很可能找不到一条垃圾文本;另一方面,运用现有关键词规则找出的样本都非常相似且准确率不高,达不到扩充标注样本的目的。
2)广告样本与正常聊天内容高度相似
游戏中的垃圾文本多数是一些广告形式的内容, 这些内容与玩家的正常聊天有很高的相似性。比如:”1块钱10m” 是SLG游戏中很常见的广告, 是在描述某种资源的价格, 但是正常玩家的发言也可能会有类似的内容, 比如”老区一块钱十米银都有”, 这只是玩家在谈论资源价格, 并不属于广告,这样的样本通过关键词规则很难进行区分。
对于文本分类模型而言, 需要模型学到前后文的语义信息,然而直接训练的文本分类模型通常会关注一些关键字或是关键词特征, 使得模型容易误伤。
2. 特定领域的预训练模型
因此,我们使用了预训练技术,能在一定程度上解决上述的问题。
2018年bert等预训练模型发布以来, 预训练+微调逐渐成为了nlp任务的标配。预训练技术可以在不使用标注数据的情况下, 学习到字符级、词级、句子级甚至句间关系的特征, 从而为下游任务打好基础。
以bert为例, 通过masked language model task学习到了句内特征, next sentence prediction task学到了句间特征。下游的运用也十分简单直接, 对于文本分类任务就只需要使用输出序列的第一项作为句子表示, 再接上分类层即可。同时, 一些应用实例表明, 预训练模型的微调只需很少的数据就可以达到较好的分类性能, 从而解决了缺乏标注数据的窘境。
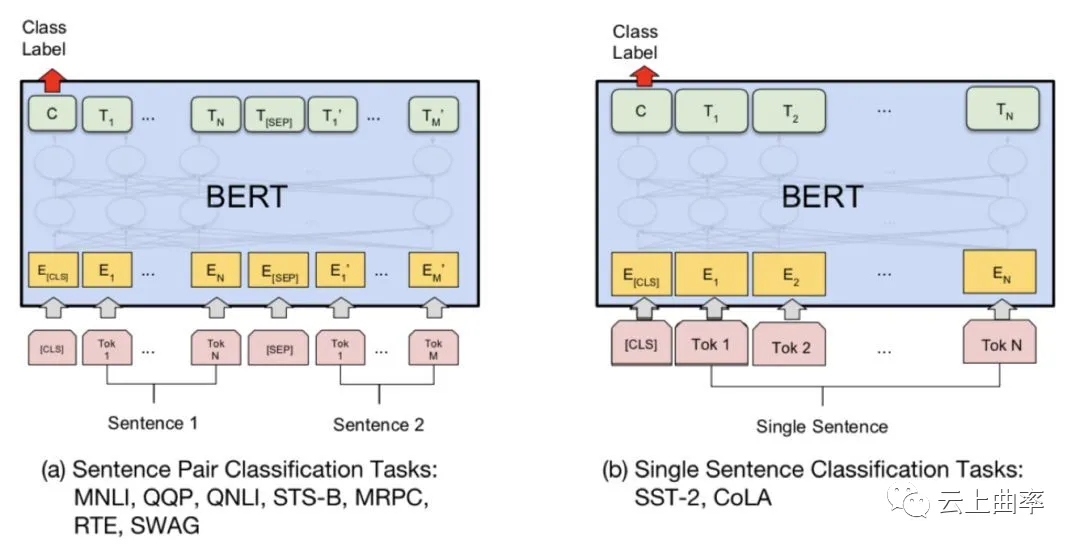
但是在实际的生产环境中运用bert会遇到一些问题。首先, google官方发布的bert模型是基于wiki,新闻等数据训练的, 这些数据中的语言表达相对正式, 而游戏中的文本会显得十分口语化, 各种缩写, 网络用语等都十分常见; 其次, 官方发布的bert模型会占用较多计算资源, 在相对廉价的cpu上很难做到实时预测。
因此, 我们在游戏聊天文本上预训练了一个小型的模型, 与官方的bert模型相比, 主要有两点不同:
- 为了可以在线上进行实时预测, 使用了4层4头的小型transformer模型
- 预训练任务剔除了next sentence prediction, 因为聊天文本很少有上下文关系
最终, 在一张V100 GPU上, 训练了21小时模型收敛, mlm task的准确率为52%
3. 模型微调
通过简单的关键词匹配, 我们选取了2000条疑似的广告样本进行标注, 其中约200条是广告, 将这200条作为正样本, 然后在全体的聊天文本中随机采样作为负样本进行训练, 采样比例为1:100, 最终模型在测试集的准确率可以达到95%以上, 部分结果如下:
一毛一毛,我卖粮食,一毛一米->广告:0.6619289
这样啊,那我等1块钱10m的吧->广告:0.18339549
模型可以很好的区分谈论违规行为与真正广告之间的区别, 基本做到不误伤正常用户。
实际应用
游戏聊天频道中,有快速动态产生的大量文本,既包含了正常玩家的聊天内容,也包含了垃圾广告内容,如何在快速变化的海量文本中,通过少量的标柱数据,实时精准识别广告?云上曲率的文本检测服务,解决了以上难题,通过集成多种机器学习技术,一方面从聊天内容中去判断,识别文本中的垃圾内容,另一方面能够根据玩家发言话题的重复去判断,有效识别机器刷屏现象。此外,除了能识别聊天中的广告外,还支持识别玩家昵称、签名、公会介绍等所有UGC部分(如图所示)。


敬请关注:
云上曲率公众号