-
Products
-
Solutions
-
Trial

-
Docs
-
About Us


 Metaverse
Metaverse 说起游戏和谐这件事情,其实已经是老生常谈了,像游戏聊天、社区论坛、直播弹幕等UGC平台都需要考虑内容安全问题,一般的应对策略是关键词屏蔽、规则过滤等,虽然这种方式确实能鉴别出大量的垃圾内容,但存在各种问题;如果应用是面向全球用户的,各国家对敏感内容的要求不同,这加大了开发者自行过滤的困难。
一、敏感词屏蔽的困境
第一,可添加的关键词数量有限,无法识别变形的敏感词,如fuck这个词,玩家可能会输入fucks,fucking,fck等多种形式。
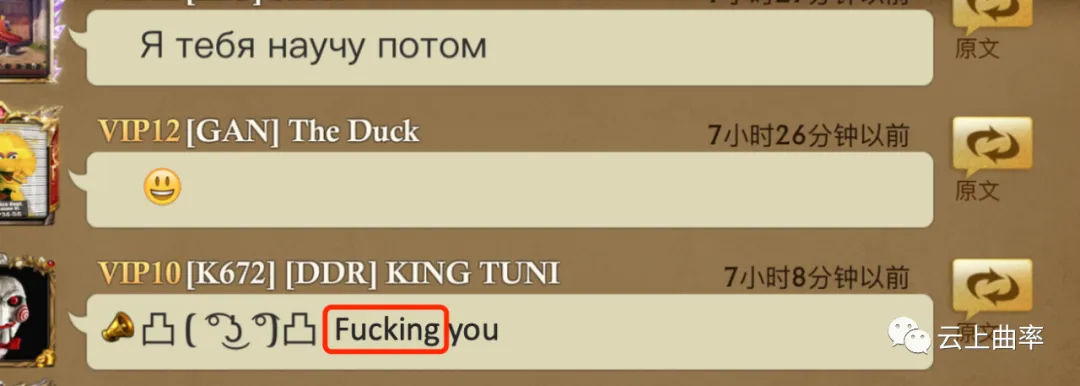
第二,关键词匹配的方式无法通过上下文进行判断,如当敏感词库中含“草",那么玩家在输入“粮草先行”,会变为”粮*先行”;对于英语的敏感词“ass“,关键词匹配的方式会将玩家输入的”pass”变为”p***”,给玩家的日常交流造成障碍,影响游戏体验。

第三,对于多语言的游戏,关键词匹配的方式无法根据玩家输入的语种进行判断。例如,在土耳其语中,am是个敏感内容,要被屏蔽掉,但如果玩家输入的语言是英文时,该词也会被屏蔽掉(即便am在英文中不是敏感词)。

二、人工智能技术让敏感词屏蔽更精确
那么如何高效识别复杂语义下的垃圾文本呢?这时候我们就要依托语义分析来处理辨别。语义分析是依托深度学习技术和大数据技术,从亿级垃圾特征库中提取和不断添加新特征,通过反复学习更有用的特征,来达到对复杂语义中垃圾内容的精确判定。
具体来说,云上曲率的文本反垃圾是这样来实现的:
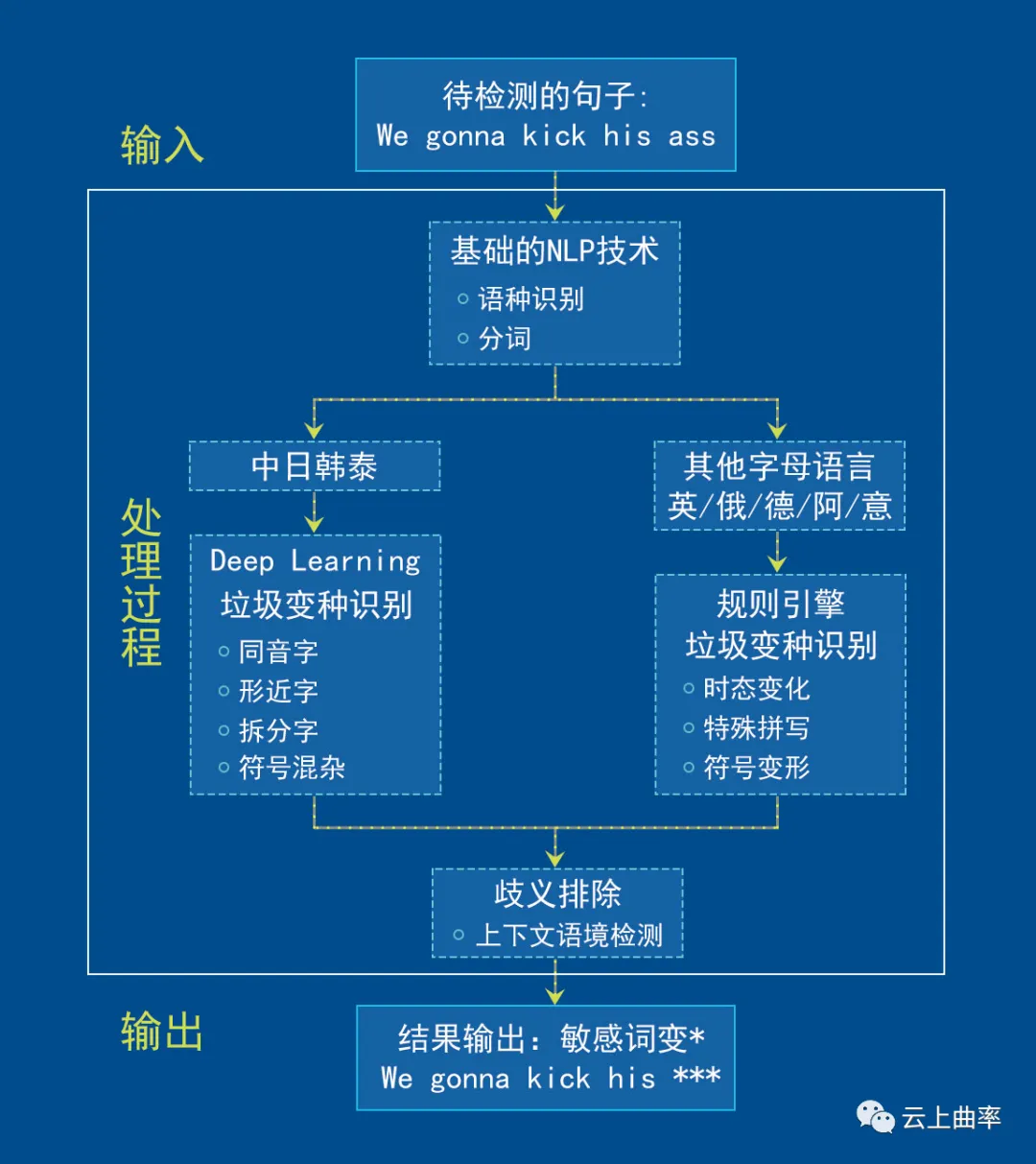
第一步:对要检测的句子进行预处理、语种识别以及分词处理,通过预处理技术处理输入中的空白字符、多空格、URL、Email、表情串等内容。
第二步:对不同的语言建立不同的算法模型,去判断语句中是否含有敏感词;针对中文、日文、韩语、泰语这些字符型的语言,通过“word embedding“计算文字的相似度,判断是否有同音字、形近字、拆分字等变体形式;对字母语言如英、俄、德、意、阿语等,会通过语言规则检查时态变化、特殊拼写等内容;
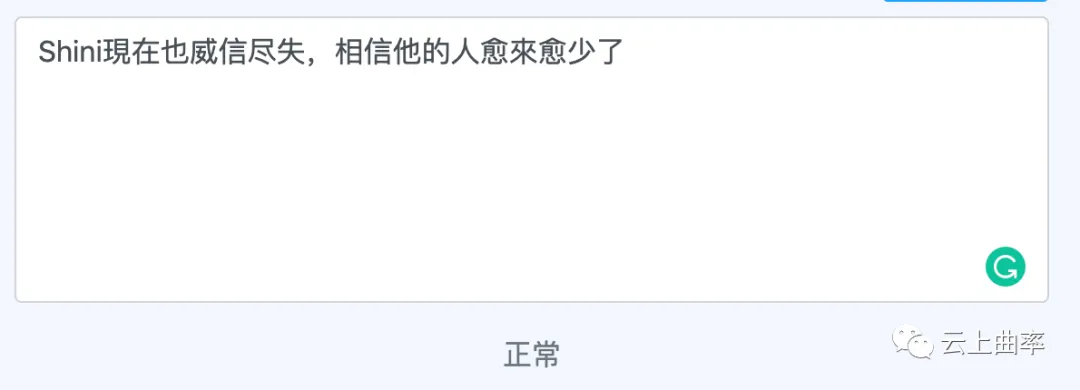
第三步:对命中的敏感词会通过“动态词向量的相似度算法”进行上下文语境判断,进一步确认是否需要屏蔽。如下图所示,虽然两个句子都是威信,但能准确识别出哪种语境下是微信的变体。
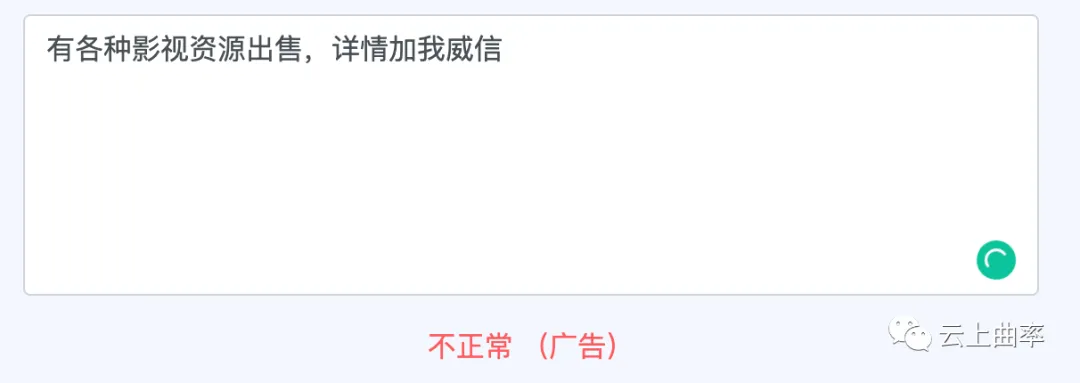
云上曲率本身作为海量内容拥有者,以及多年的数据和技术沉淀,为文本反垃圾系统提供了一个庞大的训练用数据库,这也是云上曲率文本检测服务所拥有的天然优势。此外,面对不同国家不同地区不同的文化差异,我们也积累了数万不同语种的敏感词汇,加上我们的规则引擎、深度学习、迁移学习等多种算法模型以及专业语言工程师的辅助审核,可以精准的筛出游戏中的广告/谩骂/涉政/色情/歧视等词句,还游戏健康绿色的聊天环境,更能规避因敏感词问题导致游戏被警告处罚甚至下架的严重问题。

敬请关注:
云上曲率公众号