-
Products
-
Solutions
-
Trial

-
Docs
-
About Us


 Metaverse
Metaverse 众所周知,印度作为世界第二人口大国,是世界上发展最快的国家之一,经济增长速度引人瞩目。同样印度的互联网市场也处在一个高速发展的阶段,截至2021年上半年,印度拥有近7亿的互联网用户,位居世界第二。每年还会新增超过一亿的互联网人口。互联网渗透率为55%,还不及仅有3亿人口的印尼。在印度,人们平均每天花费7小时上网冲浪。而他们在网络上最常做的事就是社交、游戏和看视频。这样的互联网用户基础,无疑蕴含着巨大的商机。
但语言问题就像一个“幽灵”始终困扰着印度社会。目前印度宪法承认的全国性官方语言分别为:印地语与英语,但除此之外,官方还承认了多达21种地区性官方语言,形成了“多语共存”、“多语竞争”的语言困局,也让印度成为了语言情况最为复杂的国家之一。
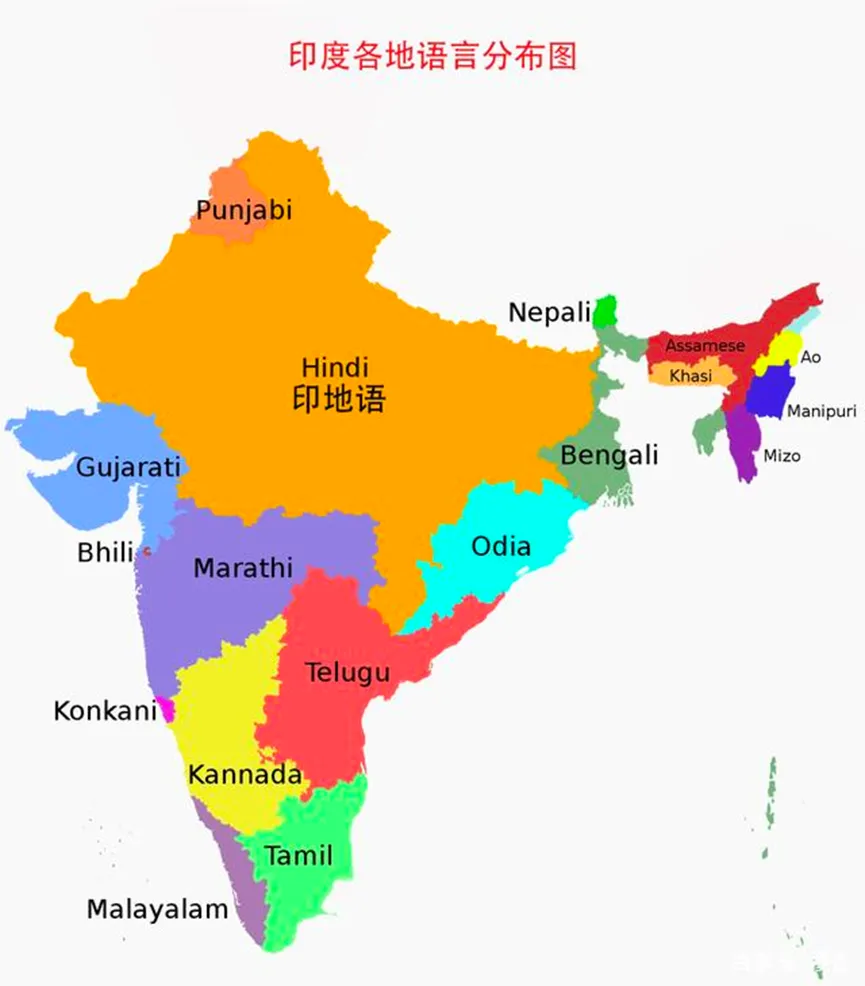
印度各地语言分布图
语言之惑:印地语 vs 英语
印地语与英语虽然均被定义为全国性的官方语言,但英语对于印度来说毕竟是一种外来语言,所以在印度基本没有以英语为母语的人口存在。根据2011年印度人口普查数据(迄今最近的一次人口普查),当时在印度大约只有1.3亿人真正会说英语,这个比例仅占印度总人口的10%左右。但因为英语在印度具有官方地位,所以印度许多政府的文件,以及一些跨地区的活动中都会使用英语,而且印度的政府官员有许多会说英语,所以虽然英语在印度总人口中的普及率虽不算高,但在其上层社会中确实还是一门比较重要的沟通语言。
而印度的另外一个官方语言印地语,作为世界上使用人数最高的第三种语言,目前在印度可以说是最接近国语的语言了。根据2011年的统计数据,印度全国有5.28亿人以印地语为母语,在当年占印度总人口的43%。另外还有1.63亿人将印地语作为第二和第三语言,具备一定的会话能力,同时在美国、南非、新加坡等地,使用印地语的人数也高达数百万。随着印度的国际地位日益提升,印地语的影响力也正在逐渐增大。
语音控制技术接受程度最高的地区
据2018年美国营销公司 iProspect 的一份报告显示,语音控制技术在亚太地区的普及度呈明显上升趋势,其中印度、中国、印尼上升趋势最为明显。这里的用户大多喜欢尝试新鲜事物,同时愿意推广语音控制技术。该报告表明,亚太地区语音控制技术尤其常用于智能家居设备及虚拟助手,有近62%的受访者在半年内使用过语音控制技术。
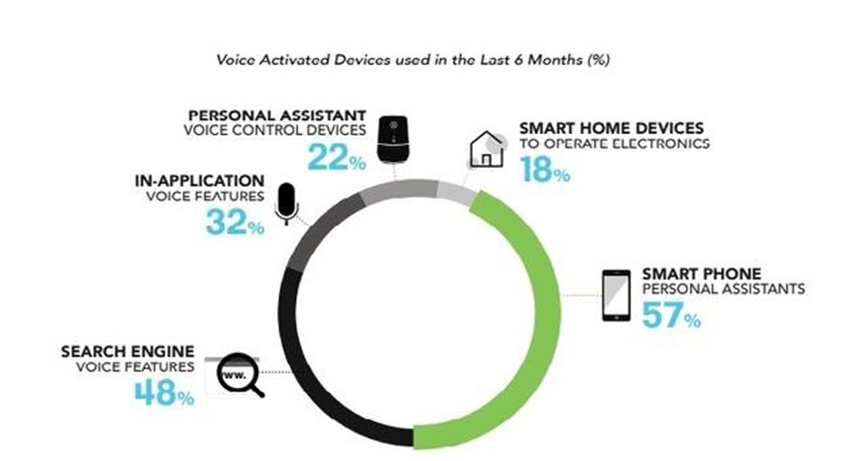
亚太地区常见使用语音控制技术的设备
在印度有82%的受访者在最近半年使用过语音控制技术,成为对语音控制接受度最高的地区。其中有51%的用户每天使用语音控制技术。受访者中没有使用语音控制技术的用户,绝大部分也都有尝试体验的计划。
纵观印度市场,使用语音控制技术的原因可谓多种多样,排在前两位原因分别是“能够同时做几件事”和“可以更高效地利用时间”。有46%的用户使用语音控制技术是因为“感觉很酷”;54%的用户则认为语音控制是下一场技术革命的一部分;在使用语音控制技术的用户当中有31%的用户通过语音控制技术进行“购买商品或预约服务”。
实现全面本地化,语音技术面临严峻挑战
语音技术已经成为人们信息获取和沟通最便捷、最有效的手段,全球的科技企业纷纷加大了在语音技术领域的投入,随着语音技术的快速发展,未来可能彻底改变社会运作的方式。
如今,印度大多数网站和应用的操作语言正在发生变化,在线产品或服务都在向印度本地的语言过渡。而在语音技术领域,想要实现对一种语言的精确识别,就需要足够的数据进行训练,但由于印地语语音识别资源的极度稀缺,让这条本就坎坷的“必经之路”变得更加崎岖。
开放印地语语音识别代码与数据集
印地语语音识别资源的稀缺主要体现在以下两方面:
1)数据集较难获取,少数开源的数据集领域单一
2)公开代码较少,文献上的结果很难复现。
为了丰富相关资源,云上曲率决定开放部分印地语数据集与相关训练代码,感兴趣的小伙伴们可以体验起来,希望可以得到更好的结果。
本数据集由 54h 训练集和 6h 开发集组成。数据来源主要为印地语新闻、视频节目以及 vlog,我们对数据集做了一定的清洗和校验。数据集领取方式:关注公众号后,发送“印地语数据集”即可领取!
下面我们就针对模型和训练细节进行简单的介绍:
1
建模单元
印地语语音识别常用的建模单元有音素,char 和 sub-word。其中音素在传统方法中使用较多。使用音素建模需要掌握基本的印地语语言学知识和印地语相关的传统语音处理工具,上手的门槛较高。端对端方法则往往使用 char 或 sub-word。在我们的实践中,使用 sub-word 训练收敛难度更大,需要做一些更细致的调参。而使用char 建模收敛更为容易,因此在此次开源的代码里我们选择了使用 char 单元建模。
2
模型结构和训练参数
在训练框架上,我们使用的是最近比较流行的 wenet。模型结构则选择了比较经典的 conformer-transformer 架构。印地语训练对模型参数大小和学习率比较敏感,小数据量用小模型收敛的更好。在实践中,我们选择了 librispeech 的模型和参数配置。几项比较重要的参数配置如下所示:
最终收敛完成后,hindi_dev 测试结果 WER 为 23.8%
# encoderencoder: conformerencoder_conf:output_size: 256 # dimension of attentionattention_heads: 4linear_units: 2048 # the number of units of position-wise feed forwardnum_blocks: 12 # the number of encoder blocksdropout_rate: 0.1positional_dropout_rate: 0.1attention_dropout_rate: 0.0input_layer: conv2d # encoder input type, you can chose conv2d, conv2d6 and conv2d8normalize_before: truecnn_module_kernel: 15use_cnn_module: Trueactivation_type: 'swish'pos_enc_layer_type: 'rel_pos'selfattention_layer_type: 'rel_selfattn'# decoderdecoder: transformerdecoder_conf:attention_heads: 4linear_units: 2048num_blocks: 6dropout_rate: 0.1positional_dropout_rate: 0.1self_attention_dropout_rate: 0.0src_attention_dropout_rate: 0.0# learnergrad_clip: 5accum_grad: 1optim: adamlr: 0.004scheduler: warmuplrscheduler_conf:warmup_steps: 25000b
具体参数配置和代码详见开源代码https://github.com/heronera/wenet/tree/main/examples/hindi_speech/s0
云上曲率(LiveData)作为全球多语言内容风控与智能翻译领域的领军企业,支持全球24种语言的内容安全风控以及30余种语言的智能翻译,针对印度地区用户主要使用的英语、印地语语等均可提供有力支撑。帮助出海印度的中国应用轻松突破语言屏障,全程守护内容合规安全。

敬请关注:
云上曲率公众号