-
Products
-
Solutions
-
Trial

-
Docs
-
About Us


 Metaverse
Metaverse 近年来,在全球经济发展放缓的背景下,泛娱乐与游戏出海领域逆势增长且成绩斐然,成为经济发展的新力量。但是,不同国家、地区的政策、文化、宗教等差异给出海应用的内容安全提出了新的挑战,要求应用本身能够快速的适应各种情况的变化,适时的根据不同场景要求对违规内容进行过滤。
随着人工智能的不断发展进步,以过滤色情内容为例,利用AI模型进行自动化鉴黄具备快速、高效、成本低等优势,但“AI鉴黄师”能够合格上岗的前提,是需要获取足够多的学习内容,即含有色情标注的样本。这就要求人类鉴黄师标注出大量精神污染和令人不适的图片,才能帮助”AI 鉴黄师“成为可以应对各类复杂情况的“老司机”。
人类鉴黄师的标注样本毕竟是有限的,理想的AI模型应该利用人类传授的有限知识,对浩如烟海的线上数据“学以致用”,在没有老师指导的情况下,提升自己的鉴黄能力。因此,我们将半监督这种学习模式,引入到AI鉴黄模型的训练,减轻人类鉴黄师压力的同时,还能使模型学习到标注数据没有传授的新知识、新场景,真正做到“无痛”鉴黄。
当鉴黄师是怎样的体验?
随着初代鉴黄师唐马儒的走红,鉴黄师这一职业也随之进入了大众的视野。鉴黄师们凭借多年的“高速驾驶“技巧,对各类色情内容拿捏自如。很多人都天真地认为“鉴黄师”是一个很轻松、很安逸、很刺激的”高福利“工作。

事实上,鉴黄师并不像外界传言的那般舒适,而是一个令人感到绝望和痛苦的工作。在实际工作中经常会面临一些极端画面,这些内容远远超出常人的承受能力。除去色情内容外,还存在大量的恐怖、血腥、恶心等场景。2020年,印度某外包公司3000名内容审核的员工发起了一宗集体诉讼,由于他们长期观看了大量令人不适的色情、暴力内容,引发了心理创伤以及创伤后应激障碍(PTSD)。
不仅是精神压力,鉴黄师的身体健康也面临威胁。据调查,一个审核工作人员平均8小时内要浏览数万张违规图片、处理至少2.5万条帖子发言与数几千条语音内容,并在秒级响应的时间要求内,准确判断内容是否违规以及违规级别,并做出相应的处理,将肮脏负面的内容拒之网络世界之外。太多挑战心理承受极限的内容加之高强度的工作压力,让鉴黄师的工作苦不堪言,生活支离破碎。

某鉴黄师的自述

纪录片《网络清道夫》剧照
半监督学习,人类鉴黄师的救星?
面对不堪重负的工作压力和心理阴影面积不断扩大的人类鉴黄师,AI鉴黄师能否自己从数据中学习知识,减少人工标注的压力呢?为此,我们将半监督学习方式引入到AI模型的训练之中,减少标注员的工作量的同时,让AI鉴黄师具备超越人类驾驶员的“车速“。
半监督学习(semi-supervised learning)是当前深度学习发展的一个新的方向,它与主流的监督学习方式相比,只需要少量的标注数据,结合大量的无标注数据,训练出具有与监督学习相比更加强大泛化能力的模型。半监督学习是一类更加接近于人类的学习方法的学习范式。一个实习鉴黄师,只要老司机进行一两次的指导,就能很准确的判断出色情和性感的区别,并且能够通过不断审核新的场景来进一步提升分辨能力。整个过程抽象出来与半监督学习思想十分相似。
近年来,在全球计算机视觉顶流会议中有关半监督的研究与论文内容与日俱增。总体来说,半监督的研究主要基于两个方向:第一种是基于熵正则化的伪标注方法,2013年发表于 ICML (国际机器学习大会) 的一篇文章论证了通过简单自训练产生的伪标签可以提升模型的泛化能力,损失函数中引入无标注损失项来实现熵正则化。2021年Google发表于 CVPR (国际计算机视觉与模式识别会议) 的文章,提出了一种教师模型、学生模型都在训练中进行优化的基于伪标签的优化方法,首次将 ImageNet 准确率提升至90%;第二种方法是基于聚类假设的一致性方法,以2017年发表于 ICLR (国际学习表征会议)的文章和2018年 NIPS (神经信息处理系统大会) 的文章为代表,它们都基于聚类假设这一思想,即如果对一个未标记的数据添加任意的扰动,则预测不应发生显著变化。

pi-model半监督框架
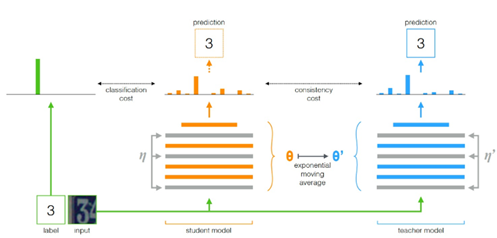
mean teacher半监督框架
虽然在训练阶段仍然大规模给AI投喂色情内容,但无论是训练数据还是线上的色情图片,只是海量数据中的一小部分。所以实际上岗的AI鉴黄师,无异于在图片的海洋里”大海捞黄“。所以准确率越高的模型,能够判断其鉴黄能力越强吗?当然不是,就算其准确率达到99.9%,但也可能是根本不是”老司机“,因为当线上色情图片的比例小于0.1%,AI鉴黄师就算躺平摆烂,把所有图片都判定为正常,准确率也可以达到99.9%。

数据不平衡可能使模型“躺平”
这就是机器学习任务中的数据不平衡问题(也称为数据长尾分布)。发表于2020年NIPS 的文章提出了半监督学习可以提升模型在长尾分布问题上的表现,文章提出使用未标记样本有助于建模更加清晰的类边界,扩大类间距离,尤其是对于尾类样本。传统的监督学习对于尾类样本,由于数据密度较低,模型学习过程中不能对这些低密度区域很好的进行边界建模,从而造成对这类数据的“模棱两可”,使得泛化性能较差;而半监督学习引入大量无标记数据可以有效提升低密度区域的数据量,更强的正则化方式使类边界更加明确,减少模糊性。
云上曲率的半监督学习应用
半监督学习想要得到高性能模型也是需要付出很大代价的,以 Google 提出的 meta pseudo labels 方法为例,无标注数据使用了 Google 自有的 JFT 数据集,这个数据集含有3.5亿高分辨率图片。为了训练如此庞大的数据集,Google 使用了 512个 TPUv2 cores,标注样本的 batch size 设置为 4096,无标注样本 batch size 为32768。共训练了800个 epoch,时间为10天,如此庞大的训练资源并不是所有企业都能满足的。
为了适应生产环境中快速迭代部署的要求,我们将整个训练过程分为两个部分:
监督学习阶段:利用人工标注的图片训练一个性能比较好的监督模型;
半监督学习阶段:海量的无标注数据经过一系列预处理方法对监督学习阶段的模型进行半监督学习,进一步提升模型预测能力。
我们借鉴了 ICML、ICLR、NIPS 相关内容中提及的两种思路相结合的半监督方法,使用损失函数中加入无标注损失项实现熵最大化原则,并且分别对无标注数据进行弱增强和强增强,通过约束模型使两者的输出不变,体现 ICLR 与 NIPS内容中所阐述的相似样本一致化原则。同时为了克服半监督学习收敛速度慢,迭代周期长的缺点。我们在半监督训练过程中,只针对性训练具有高级语义的高层模型参数,大大提升了半监督模型的迭代优化效率。从获取新场景线上无标注数据,到完成整个优化流程上线更新,预计能在3天之内完成。
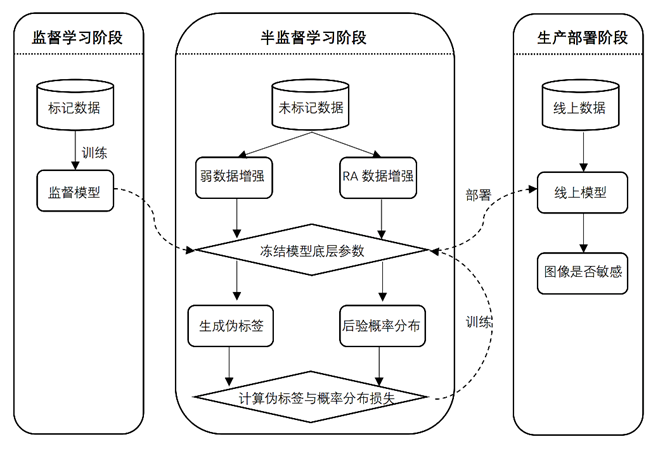
云上曲率”AI鉴黄师“训练部署流程
AI鉴黄师真的可以完全取代人类吗?当然不是,色情水太深,AI鉴黄师依然还存在把握不住的情况。但是通过我们半监督方法训练出来的鉴黄师,不仅大大减少了训练的标注成本,减轻标注员的压力,还表现出了对一些新场景、新情况、新需求极强的适应能力。相信随着不断迭代优化,云上曲率”AI鉴黄师“终有一天能成为超越人类的地表最强“老司机”。
参考文献
[1] Lee D H . Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks. 2013.
[2] Pham, Hieu, et al. "Meta pseudo labels." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[3] Laine, Samuli, and Timo Aila. "Temporal ensembling for semi-supervised learning." arXiv preprint arXiv:1610.02242 (2016).
[4] Tarvainen, Antti, and Harri Valpola. "Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results." Advances in neural information processing systems 30 (2017).
[5] Yang, Yuzhe, and Zhi Xu. "Rethinking the value of labels for improving class-imbalanced learning." Advances in neural information processing systems 33 (2020): 19290-19301

敬请关注:
云上曲率公众号