-
Products
-
Solutions
-
Trial

-
Docs
-
About Us


 Metaverse
Metaverse OCR作为图片理解的基石技术,原指光学字符识别(Optical Character Recognition),现泛指图像文字识别,即从图像视频中自动识别文字内容,属于 AI 计算机视觉领域的一个重要分支。移动互联网的爆炸式增长以及深度学习技术的普及,分别从业务需求与技术支撑两方面,进一步推动了 OCR 技术的发展。OCR 技术已深入行业的各个角落:广告推荐系统图像内容的提取、图片、视频内容的审核过滤、医学影像识别、证件识别、文档识别、街景路牌识别等等。 在泛娱乐出海的众多应用场景中图片与视频内容中经常会出现多种语言,利用单一的给定先验语种,再由相应语种的 OCR 文字识别模型进行文字识别的方式已无法满足场景需求,因此需要模型学会自动划分图片文字相应语种,即训练一个 OCR 语种识别模型作为桥梁来一同涵盖一图多语场景中所有信息内容。

传统分类任务对 OCR 语种识别进行建模,其结果往往不尽人意,因为在语种识别实际应用场景中,如果出现相似度较高的语言,例如:由假名和汉字组成的日文,经常与中文雌雄难辨;天城文、泰米尔文、马拉雅拉姆文等同属印度地区文字,此类具有较高相似特征的文字会使模型感到疑惑。
海天瑞声和清华大学联合发起的东方语种识别竞赛 OLR(Oriental Language Recognition),其中不少优秀的解决方案均聚焦于充分利用原始数据特征,进一步挖掘不同语种之间的差异性,即利用 ASR 在提取声纹特征的同时又考虑了序列特征,以提升模型判别能力。
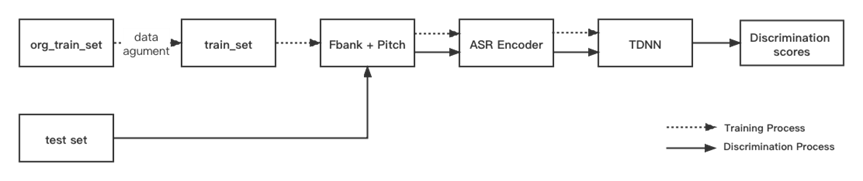
受此启发,OCR 语种识别场景亦是如此,于是我们通过预先训练基于多语种的文字识别模型,然后在此基础上微调语种识别模型,以提升语种识别模型的性能,言外之意先训练一个任务目标更抽象的复杂模型,并在此基础上微调一个任务目标抽象程度较低的简模型,从而能得到更好的拟合效果,以提升多语种识别的性能。OCR语种识别的实现流程
OCR 语种识别流程主要分为人工样本合成、多语言 OCR 文字识别训练、多语言 OCR 语种识别微调三部分:
OCR 人工样本合成
由于 OCR 人工标注成本过高,目前开源的数据十分有限,主要以英文和中文数据为主。想要训练一个“还不错”的 OCR 文字识别模型,就要自给自足动手 DIY 了。
首先整理 OCR 人工合成样本的三要素:
1. 与生产场景类似且不含文字的图片数据集,作为人工合成图像文字的复杂背景。
2. 收集各类语种字典库或词典库,用于生成文字实体。
3. 获取相应语种的多种字体库,用于丰富文字风格。
至此已万事俱备,OCR 人工合成样本整体流程如下:
多语种不同风格文字图片合成流程图
多语言 OCR 文字识别模型训练
在合成大量多语种 OCR 文字识别样本之后,我们就能开始训练这个“还不错”的多语种 OCR 文字识别模型了。常用的文字识别框架包括 CRNN+CTC,CRNN+Attention等,以 CRNN+CTC 为例:
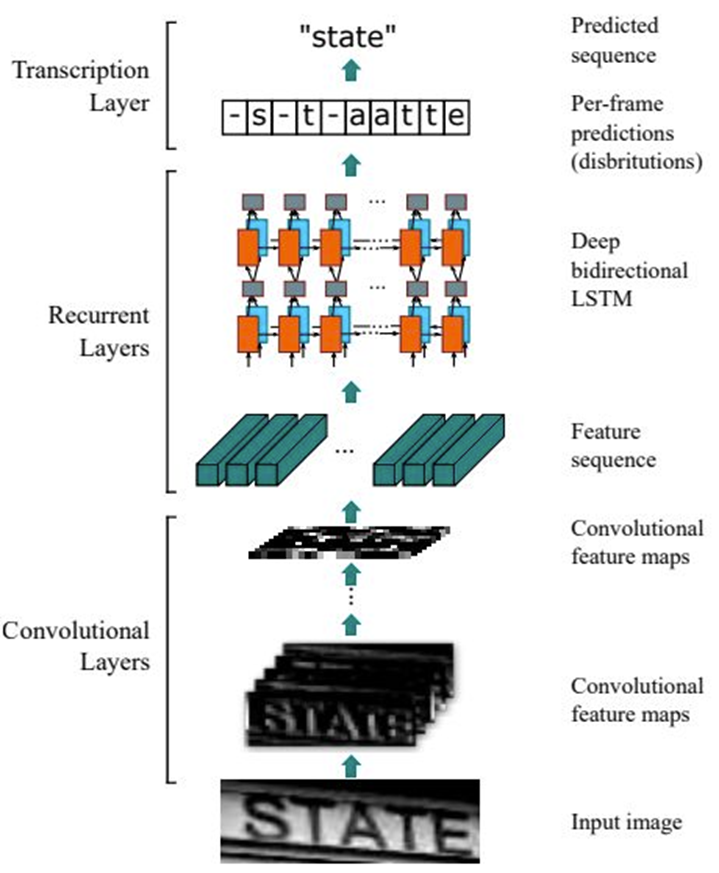
CRNN 网络结构包含三部分,从下到上依次为:
1.卷积层:使用深度 CNN ,对输入图像提取特征。
2.循环层:使用双向 RNN(BLSTM) 对特征序列进预测,输出预测标签(真实值)分布。
3.转录层:使用 CTC 损失,把从循环层获取的一系列标签分布转换成最终的标签序列。
模型结果如下:

多语言 OCR 语种识别微调
将上述训练完成的多语言 OCR 文字识别的分类器替换成相应语种的分类器,就是将 OCR 文字识别模型中 LSTM 层后面的输出相应文字的全连接层,替换成相应的语种,并用真正生产环境的数据进行微调,最终得到 OCR 语种识别模型,整体流程如下:
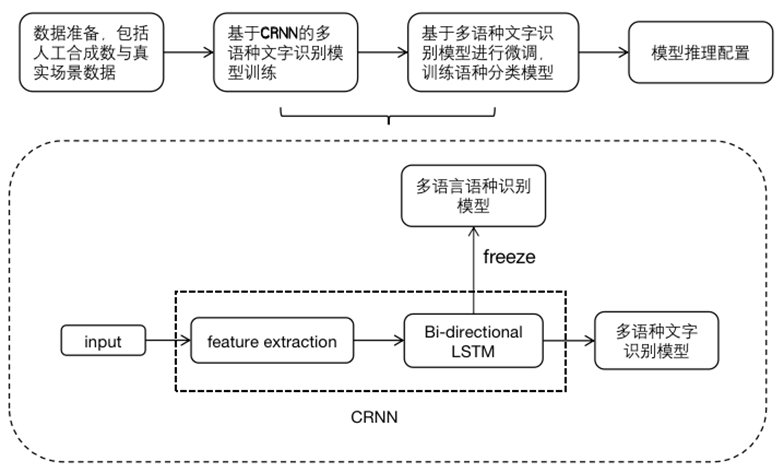
整体流程图
实践证明,相较于传统分类任务,基于 OCR 文字识别微调后的 OCR 语种识别模型在语种之间相似度较高的问题上有更优异的表现。除此之外,哪怕是未在 OCR 文字识别训练过的集外语种直接进行 fineturn ,也能得到不错的效果。其实在生产环境中,场景类型千差万别,人工合成数据的狭小分布很难覆盖所有场景,仍少不了人为的总结和数据分布的丰富,但是新的方法已经出现,怎么能够停滞不前。

敬请关注:
云上曲率公众号