-
Products
-
Solutions
-
Trial

-
Docs
-
About Us


 Metaverse
Metaverse 在今天这个快速发展的数字时代,机器翻译的需求正随着应用的全球化日益增长。特别是在应用出海的浪潮中,全球同服的游戏、社交直播等强社交属性的应用,对翻译质量的要求正变得前所未有的高。
云上曲率团队一直以来为头部出海游戏、社交应用厂商提供多语言机器翻译服务,并始终致力于提供更优质的翻译质量。如今我们骄傲的宣布,云上曲率翻译大模型现已正式推出,成为全球首个专注于翻译的百亿参数大模型。泛娱乐口语化场景下,在头部出海游戏用户的测评中,云上大模型翻译效果优于GPT4,测评结果如下:
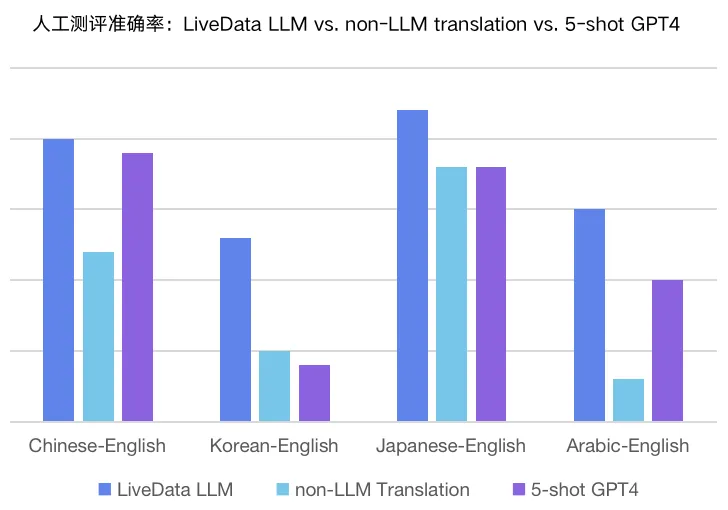
从左至右依次为 云上翻译大模型、传统翻译模型、GPT4 翻译的人工测评准确率
为什么要做翻译大模型
对于强社交属性的出海应用来说,流畅的跨语言交流不仅是用户体验的关键,更是应用成功的重要因素,直接影响了用户的付费与留存。而在游戏、社交等泛娱乐场景的口语化文本中,充满了错拼、缩写,以及只有本地人才能理解的网络用语和俚语,即便如谷歌、微软等业界巨头也难以完美应对。在这个背景下,大语言模型的横空出世无疑是一场革命,它的翻译能力,尤其是在口语化文本的翻译中,展现了惊人的流畅度和理解力。因此十分有必要将其应用在泛娱乐场景的翻译服务中。
我们是怎么做的
自大模型问世以来,云上曲率团队深入分析了包括GPT-4在内的多个大模型的成功之处,并进行了一系列的技术尝试。我们发现,对所用数据以及训练方式进行优化,能够显著提升模型的翻译能力。随着数次版本迭代,我们逐步将模型参数量扩大到了13B,数据量也达到500B Token。数据量的提升增强了模型的泛化能力,外推能力,以及对知识的利用能力,最终的翻译结果也更好。我们在泛娱乐真实场景中随机抽取了一批句子,使用近期行业内认可度很高的xCOMET对翻译进行打分,结果如下:
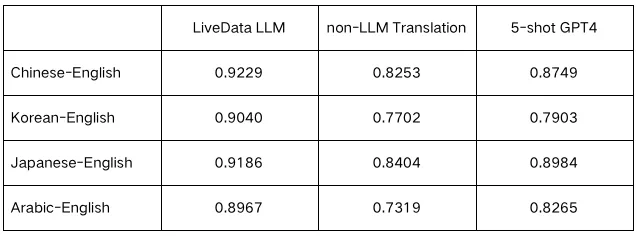
从左至右依次为 云上翻译大模型、传统翻译模型、GPT4 翻译的xCOMET评分
当然,让模型达到当前的翻译效果也并不是一蹴而就的事情,为此我们使用了多种训练和调优方式,有针对性地扩充了大量数据,我们会在下文中逐个介绍。
|Continual Pre-Training
大语言模型能够接触到的语料范围广泛,时效性强,这使得它们能够理解更多的语言现象和语法习惯。在翻译任务中,这些知识的积累对于非标准文本的处理尤为关键。为此,我们首先进行了pre-train。我们加入了大量与场景相关的单语数据,例如包含了不常见词汇的聊天数据、网络用语的解释性词典,以及我们长期以来在真实场景中积累的聊天语料等等。这些数据使得模型学习到了场景中可能涉及到的各类相关知识,为其更好地理解原文,完成翻译任务打下了基础。以下是几个实际的案例:
网络语场景
原文:我就是来吃瓜的
云上大模型译文:I'm just here to listen to gossip
原文:你买了么?巨硬的xbox?
云上大模型译文:Did you buy it? Microsoft's Xbox?
原文:那个boss的防御巨硬
云上大模型译文:That boss's defense is incredibly hard.
在上述案例中,云上曲率翻译大模型可以通过学习单语数据,能够很好地理解诸如“吃瓜”、“巨硬”等网络用语。
|Supervised Fine-tuning
此外我们对模型进行了SFT。这一步与翻译任务紧密关联,也是让云上大模型在翻译任务上实现突破的关键。我们的SFT主要分为两个部分:翻译任务和辅助任务。
对翻译任务进行SFT可以显著提高模型的基础翻译能力。在训练所用的数据方面,我们首先使用了长期积累的大量优质平行语料作为基础。其次,我们还增加了长期从翻译记录中积累的badcace数据。这相当于是给模型积累的“错题本”,模型可以借此学习到很多难点、易错点,从而进一步提升翻译能力。此外,我们还补充了大量相关任务的语料。比如通过COT以及Few-shot等方式,迭代清洗出非常多优质的平行语料。
除了提高模型的基础翻译能力之外,对于泛娱乐场景特有的问题,我们还通过SFT的方式,训练模型去执行相应的辅助任务,再次显著提高了模型翻译性能:
- 智能纠错
对于实际场景中常见的原文错拼、缩拼问题,我们专门训练模型进行智能纠错任务,将原文还原成正确的拼写,再进行翻译,以此得到更好的翻译结果。以下是几个具体案例:
原文:w.e...w.a.n.t..t.h.e...f.r.i.e.n.d...c.a.n...p.l.a.y..t.o.g.e.t.h.e.r...a.n.d...h.a.p.p.y....c.p...h.i.g.h.t...l.o.w...i...d.o.n...c.a.r.e
云上模型纠错:We want the friend can play together and happy. CP high or low i don't care
云上模型译文:我们想要能一起玩得开心的朋友。战力高或低我不在意
原文:Youcanenterourterritorybutyouhavetohavetheleader'sapproval
云上模型纠错:You can enter our territory, but you have to have the leader's approval
云上模型译文:你可以进入我们的领土,但必须得到盟主的批准
- 场景化词汇强化学习
对于用户常使用网络用语、游戏术语的现象,我们也使用了SFT的方式对模型进行了强化。与pre-train数据相结合,模型能够很好翻译出这些词汇:
游戏场景
原文:我的伤害非常刮痧
云上模型译文:My damage is very low
原文:菜就多练老弟
云上模型译文:Just practice more if you don't do well, bro
- 译后编辑任务
译后编辑任务能够利用大模型的能力,对于翻译任务的结果进行再次编辑,达到提升译文通顺度、补充缺失成分的作用。这项任务在我们的实际使用中对翻译效果的提升是十分显著的。同时,我们还通过这项任务拓展出了定制化译文风格的能力。例如在仙侠类游戏中,可以让我们的大模型翻译出古风的译文,而且风格可以切换。这项能力传统翻译模型是无法做到的,具体示例如下:
原文:We want the friend can play together and happy. CP high or low i don't care
云上模型译文:我们想要能一起玩得开心的朋友。战力高低我不在意
云上模型古风化:吾等欲觅知交共欢游,战力强弱,吾不以为意。
云上模型猫娘化:猫猫想要找到可以一起开心玩耍的朋友,战力高低猫猫不在乎喵~
原文:he said if anyone needed an explanation on how to increase power, chat him
云上模型译文:他说如果有人需要了解如何提高战力,就找他聊
云上模型古风化:他言,若有人欲寻增强战力之道,可来询之
云上模型猫娘化:他说如果有人需要解释如何提升力量的话,就去找他聊喵。
- 质量评价任务
此外,对于模型的后续迭代效率,我们也给出了解决方案。我们给模型增加了质量评价任务,让模型自己对每次翻译的结果进行包括单词级,整句级的多维度评估,便于我们快速筛选出模型翻译的badcase,这使得我们模型迭代效率提高了10倍以上。上述这些能力的引入再次为云上大模型带来了质变。
最终,在引入大量经过筛选,与场景匹配的优质数据,并专门训练模型的各种辅助能力之后,我们的大模型翻译性能产生了质变。我们的实践表明,云上曲率翻译大模型在我们关注的语种上的表现有了显著提升。与传统翻译模型相比,云上翻译大模型的优势明显,在测试的语种远超越GPT-4。这对我们来说是一个鼓舞人心的结果。
结语
未来,我们将继续探索如何利用大模型来提升其他服务的质量,满足客户需求,而不仅仅限于翻译业务。我们会继续努力,不断利用最新技术提升我们的服务质量和客户体验。我们相信云上曲率的先进技术将进一步推动泛娱乐厂商出海的进程,帮助吸引更多来自世界各地的玩家和用户,同时也为出海企业提供更专业的多语言实时互动与人工智能解决方案。
想要接入云上翻译大模型的朋友,欢迎访问云上曲率官网:www.ilivedata.com注册登记。
我们知道距离真正实现机器翻译信达雅,还有很长的路要走、很多的事要做。我们会一步一个脚印,不断根据大家的反馈,提升模型的能力。

敬请关注:
云上曲率公众号