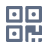-
Products
-
Solutions
-
Trial

-
Docs
-
About Us


 Metaverse
Metaverse 人的手指有指纹,一个人的声音也有声纹。熟悉的朋友在背后叫我们,我们不回头也能猜个八九不离十。湖南卫视综艺娱乐节目《蒙面唱将猜猜猜》更是将“闻声识人”展现的淋漓尽致。然而你是否了解机器其实也开始具备了很强的“听声辨人”的能力呢?
其实声纹识别的研究开展得非常早。早在上世纪四十年代,美国的贝尔实验室即开始了这方面的研究。当时的应用场景主要是针对军事领域。随着该项技术的逐步发展,司法领域也陆续开始采用,许多国家都建立了相应的规范。在深度学习兴起后,声纹识别的性能大大提高,声纹识别的应用场景也不断扩展。目前在客服、会议、游戏及泛娱乐等各种场景下,声纹识别都有大量深度的运用。随着半监督学习的发展,声纹识别的性能有望得到进一步提高,也为我们创造了更多的想象空间。
声纹识别算法的发展
人能区分不同人的声音,是因为不同人的声音有不同的特征。小孩子的声音相对尖,老人的声音相对低沉。有些歌手的声音明亮,有些则略带沙哑。机器要想区分不同的声音,也需要一些机器能懂的“特征”。
根据特征提取的方式,我们大致可以把声纹识别的发展分为三个阶段。第一阶段是先驱贝尔实验室采用的语谱图。贝尔实验室在得到语谱图后,最早是通过肉眼来分辨的。随后学界也使用更符合人发声原理的 LPC、MFCC 等。匹配方式也从肉眼发展为模板匹配和模式匹配等传统机器学习方法。这一阶段的声纹识别准确率不高。
语谱图
第二阶段是上世纪九十年代后, 基于高斯混合模型 (Gaussian mixture model, GMM) 方法逐渐成熟,成为声纹识别方向的主流。该方法可对每一个声音生成一个固定长度的向量,然后通过比较向量之间的距离来确定该声音属于谁。这一阶段声纹识别的性能相比前一阶段大幅提升,开始一步步走出实验室。
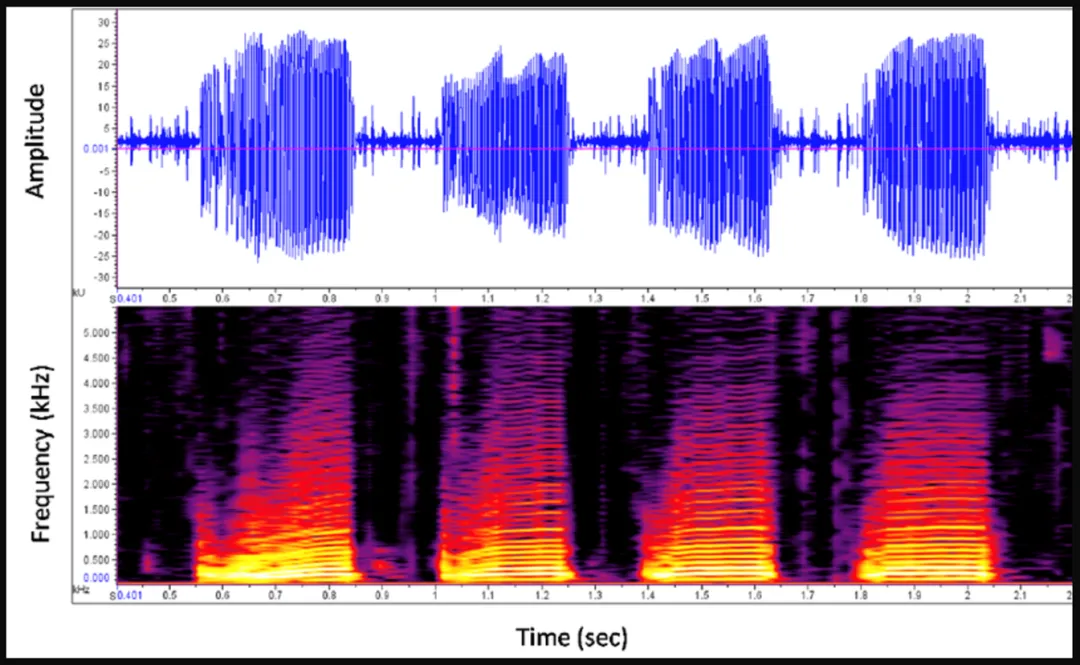
第三阶段是 2010 年后,深度学习方法的逐渐成熟使得声纹识别的性能再一次大幅度提升。深度学习的思想起源较早。早期人们模仿大脑的神经元处理信息的模式,建立了多层神经网络,并且发明了如今至关重要的误差反向传播算法(bp 算法)。然而在早期计算机的性能不足,人们难以训练一个多层的神经网络。2010 年后算力的提升以及数据量的膨胀两方面促成了该技术的开花结果。深度神经网络本身即是一个极强的特征提取器,因此可以自然地拿过来提取声纹的特征。深度学习方法的一大问题是数据依赖问题。由于深度学习本身是数据驱动的,对于场景不匹配或噪音下场景效果会大打折扣。为了解决这一问题,大家尝试了很多解决办法,比如数据增强、不同的损失函数和半监督方法等。其中基于半监督的深度学习方法是其中比较有希望的方法之一。多家机构的研究结果显示,在半监督学习的帮助下声纹识别还能有 20% 以上的性能提升。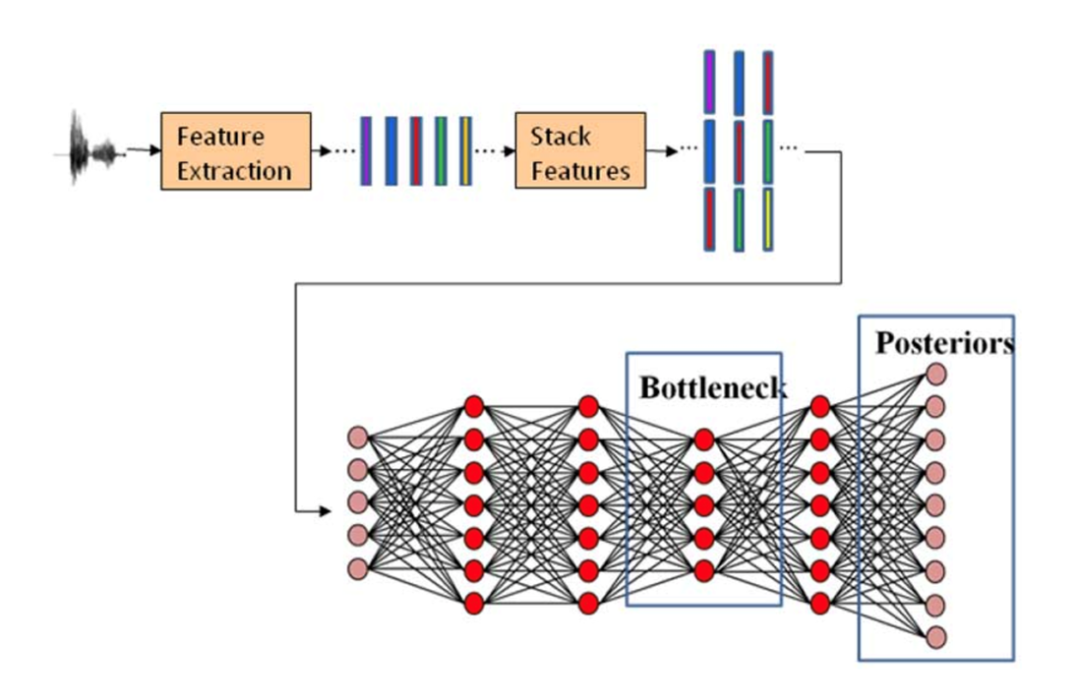
深度学习声纹识别架构
目前,关于声纹识别的研究仍然是语音处理领域的热点之一。比如基于视觉和语音两路信号的声纹识别,不但可以提高声纹识别的性能,同时也可以一定程度上做到对于特定说话人声音的提取。相信随着技术的进步,声纹识别的性能会进一步提升,从而为应用解锁更多的玩法。
声纹识别技术的应用
声纹识别的应用可以分为两大类。第一类是传统意义上的说话人识别,即确定某一句话是谁说的。第二类是以声纹识别作为系统中的一个模块,来辅助解决另一任务。下面介绍几种典型的应用场景。
1:1识别:说话人确认(Speaker verification)
即确认说话人是否为指定某人,只返回是或者不是。常用于登陆场景,在密码、人脸等验证手段之外加上声纹,能够大大提升登陆的安全性。该场景需要先注册,即需要事先得到指定人的声音的低维向量并进行存储,以进行接下来的确认过程。注册声音对结果有一定影响,通常注册多句。
1:N识别:说话人辨别(Speaker identification)
即确认说话人为多个参考人中的哪一位。常用于客服、会议场景,该场景除了需要对说话内容进行识别以外,往往还需要知道某句话是对应某个人说的这一信息。该场景需要先注册,即需要事先得到所有参考人的声音的低维向量并进行存储,以进行接下来的辨认过程。注册声音对结果有一定影响,通常每人需要注册多句。
说话人确认和说话人辨认
年龄与性别识别
声纹识别的模型同样可以作为其他下游任务的预训练模型,比如年龄、性别识别。在年龄性别数据不足够时,用一个较好的声纹识别模型做特征提取能大大降低对训练数据的需求。
人声分离
人声分离分为无重叠人声分离和有重叠人声分离两类。对于无重叠人声,只需将每句切开,再进行 1:N 确认即可。有重叠人声的分离是一个很难的问题。这一问题与语音识别中的鸡尾酒会问题基本等同。鸡尾酒会问题是指语音识别在识别一个人说话时表现较好,但是当说话的人数为两人或者多人时,语音识别准确率就会极大地降低。如果能完成重叠人声的分离,鸡尾酒问题也就不复存在。目前代表性的研究是 Google 的 voicefiter 和 Facebook 的 visualvoice。两种系统都充分利用了声纹信息去对说话人的声音进行提取,并使得语音识别的准确性得到大幅提升。
云上曲率在声纹识别领域的研究和实践上做了大量的积累。目前我们不仅有常规的说话人识别、年龄识别和性别识别,针对泛娱乐场景中容易出现的非说话语音我们也有检测识别的能力。针对视频直播场景中容易出现的色情娇喘类别,我们使用了端对端神经网络进行检测。在保持高召回的同时,还能有很低的误伤率。另外,我们也能分辨视频中是否包含音乐,以及该段音乐是不带歌词的纯音乐还是人声带歌词音乐。声纹识别作为云上曲率核心技术能力之一,在云上曲率产品矩阵中扮演着重要的角色,未来云上曲率将持续突破创新,为开发者提供全面、稳定、极致的全球实时互动与人工智能服务。

敬请关注:
云上曲率公众号